
Css3 选择器selectors—模块级别3
摘要
选择器就是匹配在树中元素的模式,且形成了用来选择XML文档中的节点的技术之一。选择器优化了HTML和XML的使用,且被设计成了可用的性能关键型代码。
CSS(层叠样式表)是一个描述HTML和XML文档在屏幕上,纸张上,语言中等渲染的语言。CSS使用选择器来绑定文档中的元素的样式属性。
文本档描述的选择器在CSS1和CSS2中已经存在了,且详细介绍了CSS3的新的选择器以及其他语言可能需要的。
选择器定义如下函数:
expression * element → boolean
那就是给定一个元素和一个选择器,本规范定义这个元素是否匹配这个这个选择器。
实际上那些表达式也能用于选择一组元素或者一组元素中的一个单独元素,通过跨越在子树中所有的元素来计算这个表达式。STTS(Simple Tree Transformation Sheets单独树转换表)——一种为了转换XML树的语言——使用这个机制。
简介
选择器级别1和选择器级别2定义了在CSS1和CSS2中分别定义的选择器功能的子集。
依赖
本规范的一些功能是特定于CSS的,或者说部分限制或者规则限制于CSS。在本规范中,这些已经在CSS2.1的条目中描述过了。
术语
本规范的所有文本都是标准的,除了例子,注意和明确标记为非标准的段落。
额外的术语在CSS2.1中定义部分定义的了。例子文档源代码和片段都是以XML(XML10)或者HTML(HTML40)语法给定的。
和CSS2的不同
本段仍是非标准的。
CSS2和CSS3选择器之间主要的不同是:
-
基本定义列表(选择器,组选择器,简单选择器等)已经变了;在CSS2中作为简单选择器的部分现在称为一系列简单选择器,且“简单选择器”条目现在用于这个系列的组件
-
元素的类型选择器,通用选择器和属性选择器现在允许有可选的命名空间组件
-
介绍了新的连接符
-
包含子串匹配属性选择器和新的伪类的新的简单选择器
-
新的伪元素和伪元素的”::”约定的介绍
-
重写了语法
-
规范中增加了集合选择器和实际上每一个规范已经支持了的定义系列选择器的档案
-
选择器现在是CSS3的一个模块了,并且是一个独立的规范;其他的规范现在能引用本文档独立的CSS
-
规范现在有了他自己的测试体系
选择器
本段仍是非标准的;他只是下边段落的集合。
一个选择器代表了一种结构。这个结构能作为确定在文档树中的哪些元素匹配选择器的条件使用,或者作为HTML或者XML片段相应的结构的平面描述。
选择器可以从一个简单元素名到丰富的上下文表示变动。
下边的表格汇总了选择器语法:
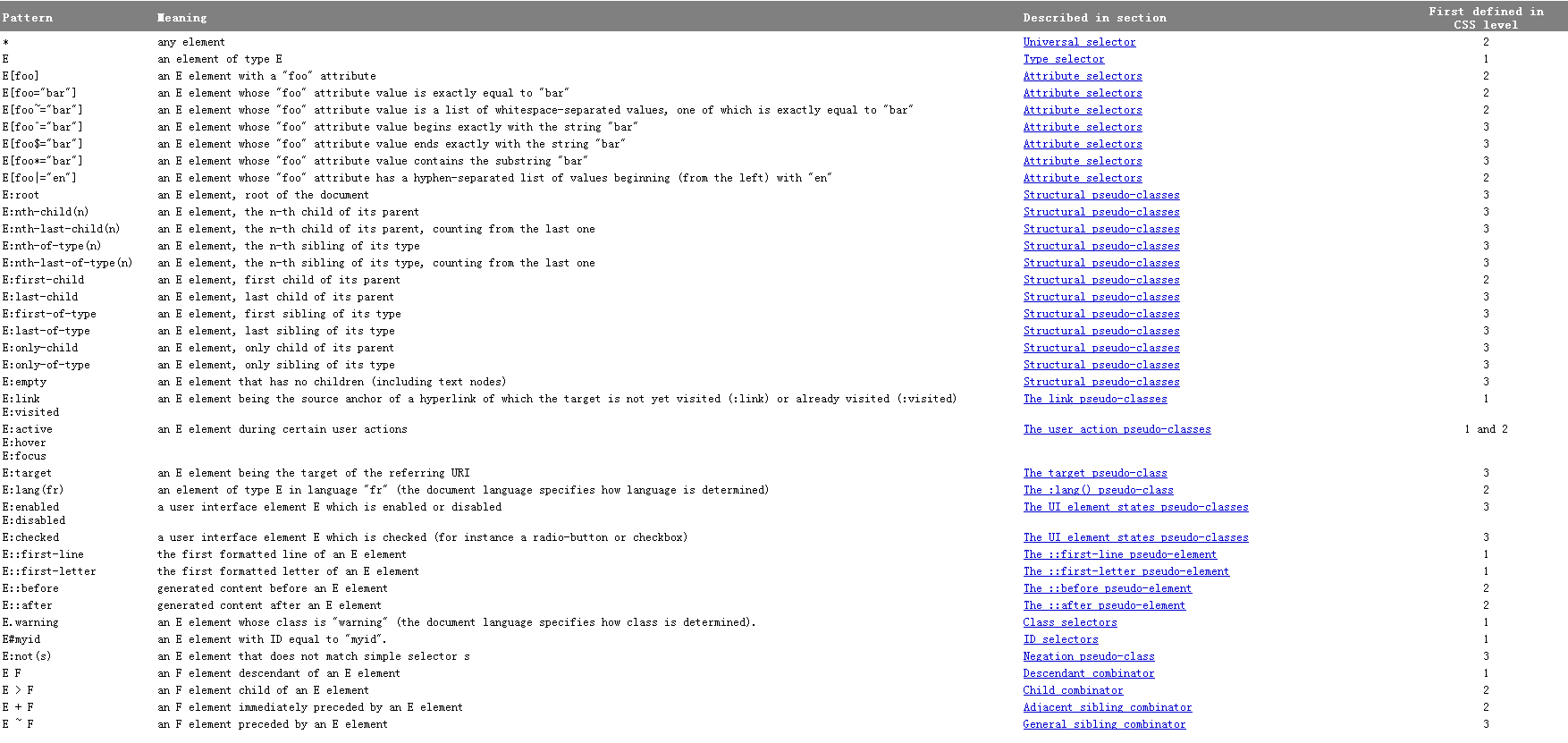
PS:顺便附上一张来自w3school的表格:
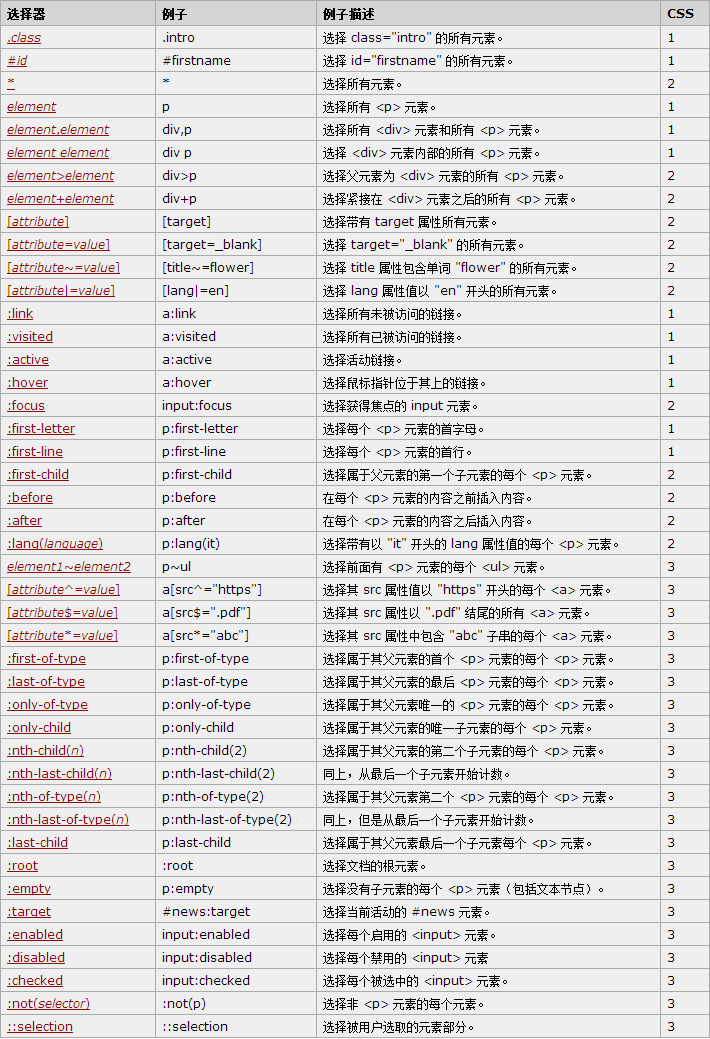
每一个选择器的含义就是源自于上边的表格中第一列匹配Meaning列的每一个单元格内容。
大小写敏感性
在ASCII范围内的所有的选择符语法都是不区分大小写的(也就是[a-z]和[A-Z]是相等的),除了不在选择器控制下的部分。文档语言元素名,属性名和在选择器中的属性值的大小写敏感性取决于文档语言。例如,在HTML中,元素名字就是不区分大小写的,但是在XML中就是区分大小写的。命名空间的大小写敏感性是在CSS3命名空间中定义的。
选择器语法
一个选择器是由按连接符分隔一个或者多个简单选择器序列组成的链。一个伪元素可以附在一个选择器的最后一个简单选择器序列之后。
一个简单选择器序列是一个不被连接符隔开的简单选择器组成链。他往往以类型选择器或者通用选择器开头。在这个序列中不允许其他的类型选择器或者通用选择器。
一个简单的选择器是一个类型选择器、通用选择器、属性选择器、类选择器、ID选择器或者伪类。
连接符是:空格,大于号>,加号+和波浪号~。空白可以出现在一个连接符和这个简单选择器周围。只有字符空格space(U+0020),tab(U+0009),换行(U+000A),回车(U+000D)和换页(U+000C)在空格中出现。其他字符,例如em-space(U+2003)和表意空格ideographic space,永远不能成为空白的一部分。
被一个选择器代表的文档树元素是这个选择器的匹配元素subjects。一个由简单选择器组成的序列而成的选择器代表了符合他要求的任何元素。在序列的最前边插入另一个简单选择器序列和一个连接符来增加额外的匹配约束,这样一个选择器的匹配元素通常是最后一个简单选择器序列所代表的元素的一个子集。
一个空的选择器(不包含任何简单选择器序列,伪元素)是一个无效的选择器。
选择器中的字符能用反斜杠通过CSS相同的转义规则转义。
某些选择器支持命名空间前缀。这种通过命名空间前缀被声明的机制应该通过使用选择器的语言来指定。如果这个语言没指定命名空间前缀声明机制,那么没有前缀被声明。在CSS中,命名空间前缀用@namespace规则声明。
选择器组
用逗号分隔的选择器列表代表了在列表中每一个单独的选择器选择的元素的并集。例如,在CSS中当有多个选择器共享相同的声明的时候,他们可以组成逗号列表。空白可以出现在逗号周围。
CSS例子:
在这个例子中,我们浓缩下边的三条独立声明为一条。因此,
h1 { font-family: sans-serif }
h2 { font-family: sans-serif }
h3 { font-family: sans-serif }
是等于:
h1, h2, h3 { font-family: sans-serif }
__警告:__这个例子中是相等的,因为所有的选择器都是有效的选择器。如果仅仅只有一个是无效的,那么整个的选择器组会是无效的。这会使得三个头元素的规则无效,对于前边的那个情况来说只有那个无效的头规则是无效的。
无效的CSS例子:
h1 { font-family: sans-serif }
h2..foo { font-family: sans-serif }
h3 { font-family: sans-serif }
是不等于:
h1, h2..foo, h3 { font-family: sans-serif }
因为上边的选择器(h1, h2..foo, h3)是完全无效的,整个的样式规则被丢弃。(当选择器没有分组,只有h2..foo的规则会被丢弃)
简单选择器
类型选择器
类型选择器就是文档语言元素类型使用CSS等同的名字语法写的名字。类型选择器代表了文档树中元素的类型的实例。
例子:
下边的选择器代表了文档树中的h1元素:
h1
类型选择器和命名空间
| 类型选择器允许可选的命名空间元件:一个已经被显式声明的可以插在用命名空间分隔符竖线(U+007C, | )分隔的元素名之前的命名空间前缀。 |
命名空间元件可以是空的(在命名空间分隔符之前没有前缀)表明这个选择器只能代表没有命名空间的元素。
星号*可以当做命名空间前缀使用,表明选择器代表了任何命名空间中的元素(包括没有命名空间元素)。
没有命名空间元件的元素类型选择器(没有命名空间分隔符)代表了不用考虑元素命名空间的元素除非有为了命名空间选择器声明的默认的命名空间。如果声明了一个默认的命名空间,那么那样的选择器只会代表了在默认命名空间中的元素。
一个包含了一个没有为命名空间选择器而声明的命名空间前缀的类型选择器是无效的选择器。
在一个识别命名空间的客户端中,元素类型选择器的部分名字(如果存在在命名空间分隔符之后的部分)会只匹配这个元素的合法名字的本地部分(也就是本地名字)。
总结:
-
__ns E__ 元素名字是E且在命名空间ns中
-
__* E__ 元素名字是E且在任何命名空间中,包括哪些没有命名空间的
-
__ E__ 元素名字是E且不在命名空间中
-
E
如果没有为了选择器声明默认的命名空间的话,这是和* E相等的。其他情况的话他是和ns E相等的,ns就是默认的命名空间。
CSS例子:
@namespace foo url(http://www.example.com);
foo|h1 { color: blue } /* first rule */
foo|* { color: yellow } /* second rule */
|h1 { color: red } /* ...*/
*|h1 { color: green }
h1 { color: green }
第一条规则(不包括
@namespaceat规则)会匹配在http://www.example.com命名空间中的h1元素。
第二条规则会匹配在
http://www.example.com命名空间中的所有元素。
第三条规则会匹配没有命名空间的
h1元素。
第四条规则会匹配在任何命名空间中的
h1元素。
最后那条规则会和第四条规则相等,因为没有定义默认命名空间。
通用选择器
通用选择器,以一个CSS合法名字和一个星号*写法作为本地名字,代表了任何元素类型的合法名字。如果没有为了选择器指定了默认命名空间的话,他代表了再文档树中中任何命名空间中的任何单个元素。如果指定了默认命名空间,请看下边的‘通用选择器和命名空间’。
如果一个被代表了的通用选择器不是一系列简单选择器组成的选择器的唯一的元件或者之后立即跟着一个伪元素,那么可以忽略且通用选择器暗中存在的。
例子:
*[hreflang =en]和[hreflang =en]是相等的,
*.warning和.warning是相等的,
*#myid和#myid是相等的。
通用选择器和命名空间
通用选择器允许一个可选的命名空间元件。按照如下使用:
-
__ns *__ 在命名空间ns中的所有元素
-
__* *__ 所有元素
-
__ *__ 没有命名空间的所有元素
-
*
如果没有指定默认的命名空间的话,这是和* *相等的。其他情况的话他是和ns *相等的,ns就是默认的命名空间。
属性选择器
选择器允许一个元素的属性表示。当一个选择器用于一个表达式来匹配一个元素时,如果那个元素有属性且匹配属性选择器所表示的属性,那么属性选择器必须考虑是否匹配这个元素。
存在属性和值选择器
CSS2中介绍了四种属性选择器:
-
[att]
代表了一个元素有att属性,但是不管这个属性的值
-
[att=val]
代表了一个元素有att属性,且值是val
-
[att~=val]
代表了一个元素有att属性,且值是空格分隔的单词列表,他们其中之一是val。如果val包含空格,他永远不会代表什么东西。如果val是空字符串,也不会代表任何东西。
-
__[att =val]__ 代表了一个元素有att属性,且值是完整的val或者以val开头且之后紧跟着-(U+002D)。这主要是为了允许语言子码subcode作为在BCP 47中所描述的那样匹配。对于lang(或者xml:lang)语言子码匹配,请看‘语言伪类:lang’。
属性值必须是CSS标识符或者字符串。在选择器中的属性名和值的大小写敏感性是取决于文档语言的。
例子:
接下来的属性选择器代表了一个
h1元素,他带有title属性,不管他的值是什么:
h1[title]
接下来的例子,选择器代表了一个
span元素,他的class属性的明确的值是example:
span[class="example"]
多个属性选择器能用来代表一个元素的多个属性,或者相同属性的多个条件。这里,这个选择器代表了一个
span元素,他的hello属性的值是Cleveland且他的goodbye属性的值是Columbus:
span[hello="Cleveland"][goodbye="Columbus"]
接下来的CSS规则阐述了
=和~=之间的区别。第一个选择器会匹配,例如,一个a元素,rel属性的值是copyright copyleft copyeditor。第二个选择器只会匹配一个a元素,他的href属性的值是确切的http://www.w3.org/
a[rel~="copyright"] { ... }
a[href="http://www.w3.org/"] { ... }
下边的选择器代表了一个
a元素,他的hreflang属性值是fr。
a[hreflang=fr]
下边的选择器代表了一个
a元素,他的hreflang属性值是以en开头,包含en, en-US和en-scouse:
a[hreflang|="en"]
下边的选择器代表了一个
DIALOGUE元素,当他的character属性值是下边两个之中的一个时:
DIALOGUE[character=romeo]
DIALOGUE[character=juliet]
子串匹配属性选择器
提供了三个额外的属性选择器来匹配一个属性值的子串:
-
[att^=val]
代表了一个元素有att属性,且值是以前缀val开头。如果val是空字符串那么这个选择器不代表任何东西。
-
[att$=val]
代表了一个元素有att属性,且值是以后缀val结束。如果val是空字符串那么这个选择器不代表任何东西。
-
[att*=val]
代表了一个元素有att属性,且值至少包含了一个val子串实例。如果val是空字符串那么这个选择器不代表任何东西。
属性值必须是CSS标识符或者字符串。在选择器中的属性名和值的大小写敏感性是取决于文档语言的。
例子:
接下来的选择器代表了一个HTML的
object,引用一个图片:
object[type^="image/"]
接下来的选择器代表了一个HTML的超链接
a,其属性href的值以.html结尾:
a[href$=".html"]
接下来的选择器代表了一个HTML的段落
p,其属性title的值包含了子串hello
p[title*="hello"]
属性选择器和命名空间
| 在一个属性选择器中的属性名是作为一个CSS合法名字(一个已经显式声明的命名空间前缀,可以通过命名空间分隔符竖线 | 分隔插入到属性名之前)给定的。复合XML中命名空间的建议,默认命名空间不会应用到属性上,因此没有命名空间元件的属性选择器只会应用到那些没有命名空间的属性上(等于|attr;这些属性被称为在“每个元素类型命名空间分区”中)。一个星号*可以用于命名空间前缀表明了这个选择器是匹配所有的不属于这个属性的命名空间的属性名。 |
一个带有包含没有显式声明的命名空间前缀的属性名的属性选择器是无效的。
CSS例子:
@namespace foo "http://www.example.com";
[foo|att=val] { color: blue }
[*|att] { color: yellow }
[|att] { color: green }
[att] { color: green }
第一条规则只会匹配属性att在
http://www.example.com命名空间中且其值是val的元素。
第二条规则只会匹配属性att,而不管这个属性的命名空间(包括没有命名空间)的元素。
最后的两条规则是相等的,都只会匹配属性att不在任何命名空间中的元素。
在DTD(document type definition)中的默认属性值
属性选择器代表了再文档树中的属性值。文档树是怎样结构化的,是在选择器的作用域之外的。在一些文档中格式化默认属性值能在DTD或者其他地方定义,但是这些只能被属性选择器选择,如果他们出现在文档树中的话。选择器应该设计为无论包不包含默认值,他们都可以在文档树中工作。
例如,一个XML用户代理UA,但是不需要读DTD的“外部子集external subset”,但需要在文档的“内部子集internal subset”中查找默认属性值。在外部子集中定义一个默认属性值可以出现在文档树中,也可以不出现,这是取决于UA的。
一个能识别XML命名空间的UA,但是不需要使用它的命名空间的知识来对待默认属性值就好像他们在文档中出现了一样。
例子:
考虑一个元素
EXAMPLE,带有属性radix,他的默认值是decimal。DTD片段可能是
<!ATTLIST EXAMPLE radix (decimal,octal) "decimal">
如果样式表包含如下规则
EXAMPLE[radix=decimal] { /*... default property settings ...*/ }
EXAMPLE[radix=octal] { /*... other settings...*/ }
第一条规则可能不会匹配
radix属性默认(没有明显)设置了的元素。考虑所有的情况,对于默认值属性选择器应该被丢弃:
EXAMPLE { /*... default property settings ...*/ }
EXAMPLE[radix=octal] { /*... other settings...*/ }
这里,因为选择器
EXAMPLE[radix=octal]不只是指定了单独的类型选择器,在第二条规则中声明的样式会覆盖第一条中匹配的那些有radix属性且值是octal的元素。在非默认情况下的样式规则中必须顾虑所有的只应用到默认情况的属性声明是会覆盖掉的。
类选择器
用HTML工作,当代表class属性时,作者可以使用“句点”符号(U+002E,.)作为一个可供选择的~=符号。因此,对于HTML,div.value和div[class~=value]有着同样的含义。属性值必须紧跟着.号。
如果UA有命名空间特性且允许他来确定那个属性的class属性来代表命名空间的话,那么这个UA可以在XML文档中使用.来应用选择器。一个这样的命名空间特性知识例子就是在规范中部分命名空间的文章中(例如,SVG 1.0描述了SVG类class属性以及一个UA应该怎样来解释他)。
CSS例子:
我们能通过如下方式来给所有的带有
class~="pastoral"的元素指定样式信息:
*.pastoral { color: green } /* all elements with class~=pastoral */
或者仅仅是:
.pastoral { color: green } /* all elements with class~=pastoral */
接下来的只对有
class~="pastoral"的H1元素指定样式:
H1.pastoral { color: green } /* H1 elements with class~=pastoral */
给定这些规则,下边的第一个H1实例不会又绿色文本,而第二个会是:
<H1>Not green</H1>
<H1 class="pastoral">Very green</H1>
接下来的规则匹配了任何class属性指定了一个空格分隔的值列表,其中包含了pastoral和marine的任何P元素:
p.pastoral.marine { color: green }
这个规则匹配class="pastoral blue aqua marine",但是不会匹配class="pastoral blue"。
ID选择器
文档语言可以包含声明为ID类型的属性。使得ID类型属性如此特殊的就是在一个一致的文档中不能有两个这样的属性的值是相同的,不管他们在什么样的元素类型上;一个ID类型的属性能用来唯一标示他的元素。在HTML中所有的ID属性命名为id;XML应用可以命名不同的ID属性,但是要应用相同的约束。
一个文档语言的ID类型属性允许作者给在文档树中的一个元素实例指定一个标识符。ID选择器包含了一个“井号”(U+0023,#),之后紧跟着ID的值,这个值必须是CSS标识符。一个ID选择器代表了一个具有一个标识符匹配在ID选择器中的标识符的元素实例。
选择器不指定UA怎样知道一个元素的ID类型属性。UA可以读一个文档的DTD,有硬性编码的信息或者问用户。
例子:
接下来的ID选择器代表了一个
h1元素,他的ID类型属性的值是chapter1:
h1#chapter1
接下来的ID选择器代表了任何元素,他的ID类型属性的值是chapter1:
#chapter1
接下来的选择器代表了任何元素,他的ID类型属性的值是z98y
*#z98y
如果一个元素有多个ID属性,他们都必须以那个元素的IDs来对待,为了ID选择器的目的。这样的一个解决方案能达到使用混合xml:id,DOM3 Core,XML DTDs和命名空间特性namespace-specific的知识。
伪类
介绍伪类概念是为了允许基于放置在文档树之外的或者不能使用其他简单选择器表达的信息的选择。
伪类往往存在“冒号”(:),跟着伪类的名字和在圆括号之间可选的的值。
伪类允许在一个选择器中包含所有简单选择器序列中。在主要的类型选择器或者通用选择器(可能会被忽略)之后,伪类允许在所有简单选择器序列的任何地方。伪类名字是不区分大小写的。一些伪类是互相独立的,然而其他的能同时在相同元素上应用。伪类可以是动态的,就当用户和文档交互时元素可以获得或者丢掉一个伪类意义而言。
动态伪类
动态伪类按元素特性分类,而不是他们的名字、属性或者内容,根本特性是不能从文档树中导出。
动态伪类不会在文档源或文档树中出现。
链接伪类::link和:visited
用户代理通常显示未访问过的链接和访问过的是不一样的。选择器提供了伪类:link和:visited来区分他们:
-
:link伪类应用到还没有访问过的链接。 -
:visited伪类应用到已经被用户访问过的链接。
过一段时间之后,用户代理可以选择返回到未访问链接:link的状态。
这两种状态是互相独立的。
例子:
接下来的选择器代表了带有类external且已经访问过的链接:
a.external:link
UA因此可以对待所有的链接为未访问过的链接,或者实现其他的措施来保护用户的隐私通过渲染不同的访问过的和未访问的链接。
用户行为伪类::hover,:active和:focus
交互式用户代理有时候会改变渲染来响应用户行为。选择器为用户作用于的当前元素的选择提供了三种伪类。
-
:hover伪类应用到当用户在指针设备上指到一个元素上时,但是没有必要激活它。例如,一个可见用户代理能应用这个伪类在鼠标光标悬停到这个元素生成的盒子的时候。不支持交互式媒介的用户代理不需要支持这个伪类。一些遵守的支持交互式媒介的用户代理可能没能力支持和这个伪类(例如,不检测悬停的笔设备)。 -
:active伪类应用到当元素被用户激活时。例如,在用户按下鼠标按钮且在释放他之间的时间段。在具有多个鼠标按钮的设备上,:active仅应用到主要的或者主要的激活按钮上。 -
:focus伪类应用到当元素有焦点(接受键盘和鼠标事件或者其他的输入形式)时。
可能有文档语言或者实现者会特殊限制那些元素能变为:active或者获得:focus。
这些伪类不是相互独立的。一个元素可以同时匹配多个伪类。
选择器没有定义如果一个是:active或者:hover状态的元素的父元素也是那种状态。
注意:如果:hover状态应用到了一个元素上,因为他的孩子是通过指针设备指定的,那么:hover应用到一个不在指针设备下边的元素上是可能的。
例子:
a:link /* unvisited links */
a:visited /* visited links */
a:hover /* user hovers */
a:active /* active links */
一个合并了动态伪类的例子:
a:focus
a:focus:hover
最后一个选择器匹配一个
a元素,他是在伪类:focus和:hover中。
目标伪类:target
一些URI引用一个资源内的一个位置。这种URI以#之后跟着锚点标识符(称为片段标识符)结尾。
带有片段标识符的URI链接到文档中的一个确定元素,以目标元素广知。例如,这里是一个URI定位到在HTML文档中的一个名为section_2的锚点:
http://example.com/html/top.html#section_2
一个目标元素能通过:target伪类代表。如果文档的URI没有片段标识符,那么文档就没有目标元素。
例子:
p.note:target
这个选择器代表了一个p元素,他的class是note且是引用URI的目标元素。
CSS例子:
这里,
:target伪类是用来使得目标元素时红色的且在其之前放一个图片,如果有的话:
*:target { color : red }
*:target::before { content : url(target.png) }
语言伪类:lang
如果文档语言指定了一个元素的人类语言是怎样确定的,那么就有可能书写选择器来代表一个元素是基于他的语言的。例如,在HTML中,语言就是通过lang属性和从meta元素或者协议中(例如一个HTTP头)的可能的信息结合确定的。XML使用一个属性,称为xml:lang,且那里可能会有其他文档语言特性方法来确定该语言。
伪类:lang(C)代表了一个在语言C中的元素。无论一个元素是否被一个:lang()选择器代表是基于唯一的这个元素的语言值和标识符C是相等的或者是以标识符C开头之后紧跟着-。匹配C和这个元素的语言值是不区分大小写的。标识符C没必要是一个可用的语言名。
C必须是有效的CSS标识符,且不能为空。(其他情况选择器是无效的)
例子:
下边的两个选择器代表了一个在Belgian French或者German中的HTML文档。两个选择器之后的选择器代表了在Belgian French或者German中的任意元素中的q块元素。
html:lang(fr-be)
html:lang(de)
:lang(fr-be) > q
:lang(de) > q
:lang(C)和‘ |
=’操作符之间的区别是‘ | =’操作符只执行和一个元素上给定的属性对照,然而:lang(C)伪元素使用UA关于文档的语义学来确定这个对照。 |
在这个HTML例子中,只有BODY匹配[lang =fr](因此他有LANG属性),但是BODY和P都会匹配 :lang(fr)(因为都在French中)。P不会匹配[lang=fr]因为他没有LANG属性。
<body lang=fr>
<p>Je suis français.</p>
</body>
UI元素状态伪类
:enabled和:disabled伪类
:enabled伪类代表了用户界面元素在可用状态下;这样的元素有一个相应的不可用状态。
相反,:disabled伪类代表了用户界面元素在不可用状态;这样的元素有一个对于的可用状态。
什么构成了可用状态,不可用状态和一个用户界面元素是依赖于语言的。在一个类型化文档中绝大多数的元素没有:enabled和:disabled。
注意:CSS属性可能影响一个用户和一个给定的用户界面元素交互的能力,但不影响他是否匹配:enabled和:disabled,例如display和visibility属性不影响一个元素的可用或不可用状态。
:checked伪类
单选框和复选框元素能够被用户切换状态。一些菜单项是”checked选中”的当用户选择他们的时候。当这样的元素切到了”on”的状态,那么:checked就会应用上。然而:checked伪类在类型上是动态的,且能通过用户行为改变,由于他也能基于文档中的语义属性是否存在,所以他应用在所有的媒介上。例如,:checked伪类最初是应用到如同在HTML4的17.2.1章节章节中所描述的HTML4中selected和checked属性的元素上的,但因此用户能切换到”off”状态,在这样的情况下:checked伪类不会再应用了。
:indeterminate伪类
注意:单选框和复选框元素能通过用户来切换,但是有时会在一个不确定的indeterminate状态,不是选中了也不是未选中。这能是由元素属性或者DOM操作引起的。
本规范未来的版本可能会介绍:indeterminate伪类来应用到那样的元素上。
结构伪类
选择器介绍结构伪类的概念是为了允许基于位于文档树中的额外信息来选择,但是不能由其他的简单选择器或者关系选择器代表。
独立文本和其他非元素节点当计算在一个元素在其父元素的孩子列表中的位置时不计算在内。当计算在一个元素在其父元素的孩子列表中的位置时,序列数字从1开始。
:root伪类
:root伪类代表了文档的根元素。在HTML4中,通常就是HTML元素。
:nth-child()伪类
:nth-child(an+b)伪类记法代表了一个元素,在文档树中在其之前有an+b-1个兄弟,n是任何的正整数或者0,且该元素有父元素。a和b的值都是大于0的,这有效的把这个元素的孩子们划分为a元素组(最后的组用剩余的),且选择每一组中的第b个元素。例如,这允许选择器定位在表格中的每一个其他行,且能用于交替循环四个段落文本颜色。a和b的值必须是整数(正的,负的或者0)。一个元素的第一个孩子的次序是1。
另外,:nth-child()还可以使用‘odd’和‘even’代为参数。‘odd’和2n+1有同样的意义,‘even’和2n有着同样的意义。
:nth-child()参数必须匹配下边的语法,INTEGER匹配[0-9]+标记,其余的标记通过句法扫描器给定。
nth
: S* [ ['-'|'+']? INTEGER? {N} [ S* ['-'|'+'] S* INTEGER ]? |
['-'|'+']? INTEGER | {O}{D}{D} | {E}{V}{E}{N} ] S*
;
例子:
tr:nth-child(2n+1) /* represents every odd row of an HTML table */
tr:nth-child(odd) /* same */
tr:nth-child(2n+0) /* represents every even row of an HTML table */
tr:nth-child(even) /* same */
/* Alternate paragraph colours in CSS */
p:nth-child(4n+1) { color: navy; }
p:nth-child(4n+2) { color: green; }
p:nth-child(4n+3) { color: maroon; }
p:nth-child(4n+4) { color: purple; }
当b的值是负的符号时,在表达式中的”+”字符必须移除掉(和用”-“字符代替一样效果,表明b的负值)。
例子:
:nth-child(10n-1) /* represents the 9th, 19th, 29th, etc, element */
:nth-child(10n+9) /* Same */
:nth-child(10n+-1) /* Syntactically invalid, and would be ignored */
当a等于0,an部分就没有必要包括在内了(除非b部分已经省略了)。当an没有包括在内且b不是负值,b之前的+号也可以省略。在这种情况下,语法简化为::nth-child(b)。
例子:
foo:nth-child(0n+5) /* represents an element foo that is the 5th child
of its parent element */
foo:nth-child(5) /* same */
当a=1或者a=-1的时候,数字可以从规则中省略。
例子:
因此接下来的选择器是相等的:
ar:nth-child(1n+0) /* represents all bar elements, specificity (0,1,1) */
bar:nth-child(n+0) /* same */
bar:nth-child(n) /* same */
bar /* same but lower specificity (0,0,1) */
如果b=0,那么每一个第a个元素都是被选中的。在这样的情况向,+b(-b)部分可以忽略除非a部分已经忽略了。
例子:
tr:nth-child(2n+0) /* represents every even row of an HTML table */
tr:nth-child(2n) /* same */
在”(“之后,”)”之前是允许出现空白的,且在分隔an和b部分(都有)的”+”或者”-“的两边也是允许出现空白的。
有效空白例子:
:nth-child( 3n + 1 )
:nth-child( +3n - 2 )
:nth-child( -n+ 6)
:nth-child( +6 )
无效空白例子:
:nth-child(3 n)
:nth-child(+ 2n)
:nth-child(+ 2)
如果a和b都等于0,伪类就不代表文档树中的元素。
a可以是负值,但是an+b只能是正值,对于n≥0,可能会代表在文档树中的元素。
例子:
html|tr:nth-child(-n+6) /* represents the 6 first rows of XHTML tables */
:nth-last-child()伪类
:nth-last-child(an+b)伪类记法代表了一个元素,在文档树中在其之后具有an+b-1个兄弟。n可以是任何的正整数或者0,该元素必须得有一个父元素。参见:nth-child()伪类部分的语法参数。他也支持‘even’和‘odd’参数。
例子:
tr:nth-last-child(-n+2) /* represents the two last rows of an HTML table */
foo:nth-last-child(odd) /* represents all odd foo elements in their parent element,
counting from the last one */
:nth-of-type()伪类
:nth-of-type(an+b)伪类记法代表了一个元素在文档树中在其之前有an+b-1个和其有相同元素名的兄弟,n的值可以是任何的0或者正整数,该元素必须有父元素。参见:nth-child()伪类部分的语法参数。他也支持‘even’和‘odd’参数。
CSS例子:
这允许作者交替浮动图片的位置:
img:nth-of-type(2n+1) { float: right; }
img:nth-of-type(2n) { float: left; }
:nth-last-of-type()伪类
:nth-last-of-type(an+b)伪类记法代表了一个元素在文档树中在其之后有an+b-1个和其有相同元素名的兄弟,n的值可以是任何的0或者正整数,该元素必须有父元素。参见:nth-child()伪类部分的语法参数。他也支持‘even’和‘odd’参数。
例子:
为了代表一个XHTML中body的所有的h2子元素,但是除了第一个和最后一个,可以使用下边的选择器:
body > h2:nth-of-type(n+2):nth-last-of-type(n+2)
在这种情况下,也可以使用:not(),尽管这个选择器最终一样长的:
body > h2:not(:first-of-type):not(:last-of-type)
:first-child伪类
和:nth-child(1)一样。:first-child伪类代表了一个元素是一些其他元素的第一个孩子。
例子:
接下来的选择器代表了一个p元素,他是div元素的第一个孩子:
div > p:first-child
这个选择器能代表在如下片段中div内部的p:
<p> The last P before the note.</p>
<div class="note">
<p> The first P inside the note.</p>
</div>
但是不能代表如下片段中的第二个p:
<p> The last P before the note.</p>
<div class="note">
<h2> Note </h2>
<p> The first P inside the note.</p>
</div>
下边的两个选择器通常是相等的:
* > a:first-child /* a is first child of any element */
a:first-child /* Same (assuming a is not the root element) */
:last-child伪类
和:nth-last-child(1)一样。:last-child伪类代表了一个元素是一些其他元素的最后一个孩子。
例子:
接下来的选择器代表了一个列表项li,他是有序列表ol的最后一个孩子。
ol > li:last-child
:first-of-type伪类
和:nth-of-type(1)一样。:first-of-type伪类代表了一个元素时他的父元素的孩子列表中的第一个他的类型的兄弟。
例子:
接下来的选择器代表了一个自定义标题dt在一个自定义列表dl内部,这个dt是他的父元素的孩子列表中的第一个他的类型。
dl dt:first-of-type
对于下边的例子中的前2个dt元素是一个有效的描述,但是对于第三个就不是了:
<dl>
<dt>gigogne</dt>
<dd>
<dl>
<dt>fusée</dt>
<dd>multistage rocket</dd>
<dt>table</dt>
<dd>nest of tables</dd>
</dl>
</dd>
</dl>
:last-of-type伪类
和:nth-last-of-type(1)一样。:last-of-type伪类代表了一个元素时他的父元素的孩子列表中的最后一个他的类型的兄弟。
例子:
接下来的选择器代表了一个表格行tr中的最后一个数据单元格td。
tr > td:last-of-type
:only-child伪类
代表一个元素有父元素,且他的父元素没有其他的子元素。和:first-child:last-child或者:nth-child(1):nth-last-child(1)一样,但是特殊性较低。
:only-of-type伪类
代表了一个元素有父元素,且他的父元素没有其他的和他一样元素名的子元素。和:first-of-type:last-of-type或者:nth-of-type(1):nth-last-of-type(1)一样,但是特殊性较低。
:empty伪类
:empty伪类代表了一个元素没有任何孩子。在文档树条目中,只有元素节点和内容节点(例如DOM中文本节点text node,CDATA node以及entity references),如果他们有一个非零长度的数据,那么他们就必须作为影响空来对待;注释,处理指令processing instructions以及其他节点不影响一个元素被认为是空的。
例子:
对于如下片段,p:empty是一个有效的代表:
<p></p>
对于如下片段,foo:empty不是一个有效的代表:
<foo>bar</foo>
<foo><bar>bla</bar></foo>
<foo>this is not <bar>:empty</bar></foo>
空白Blank
本段落故意留空。(本段可能定义:contains()伪类。)
否定:not()伪类
否定伪类,:not(X),是一个函数记法,传入简单选择器(不包括否定伪类本身)作为他的参数。他代表一个元素不是他的参数所代表的。
否定不可以嵌套,:not(:not(...))是无效的。注意由于伪元素不是简单选择器,所以他们对于:not()不是一个有效的参数。
例子:
接下来的选择器匹配了在HTML文档中的所有的不是不可用(即可用)的button元素。
button:not([DISABLED])
接下来的选择器代表了除了FOO之外的所有元素。
*:not(FOO)
接下来的选择器组代表了所有的HTML元素除了链接。
html|*:not(:link):not(:visited)
默认的命名空间声明不会影响否定伪元素的参数除非参数是一个通用选择器或者类型选择器。
例子:
指定默认命名空间到
http://example.com/,接下来的选择器代表了所有的不在那个命名空间中的元素:
*|*:not(*)
接下来的选择器匹配没被悬停的任何元素,不管他的命名空间。特别地,他对于只匹配在默认命名空间中的元素(没有被悬停的)和不匹配规则的不在默认命名空间中的元素(被悬停)是没有啥限制的。
*|*:not(:hover)
注意::not()伪类允许编写无用的选择器。例如:not(*|*),不会代表任何元素,或者foo:not(bar),他和foo是相等的,但是有更高的特殊性。
伪元素
伪元素创建了关于超出了那些通过文档语言指定的文档树的抽象。例如,文档语言不会提供机制来访问一个元素内容的第一个字母或者第一行,伪元素允许作者引用另外的难以接近的信息。伪元素也可以提供作者一种方式来引用在源文档中不存在的内容(例如,::before和::after伪元素就能生成内容)。
伪元素是在两个冒号(::)之后紧跟着伪元素名字。
::记法通过当前文档介绍是为了确立伪类和伪元素之间的区别。为了兼容已存在的样式表,用户代理也必须之前在CSS1和CSS2中介绍的一个冒号记法的伪元素。这种兼容对于在本规范中介绍的新伪元素是不允许的。
每一个选择器只有一个伪元素可以出现,如果他存在,那么他必须出现在这个选择器所代表的匹配元素subjects的简单选择器序列之后。注意:本规范将来的版本可能会允许每一个选择器有多个伪元素。
::first-line伪元素
::first-line伪元素描述了一个元素的格式化后第一行的内容。
CSS例子:
p::first-line { text-transform: uppercase }
上边的规则意味着“把每一个p元素的第一行的字母全部变为大写”。
选择器
p::first-line不会匹配任何真正的文档元素。他的确匹配一个用户代理遵循的插入在每一个p元素之前的伪元素。
注意第一行的长度取决于因子数目,包括页面宽,font尺寸等等。因此一段普通的HTML段落像这样:
<P>This is a somewhat long HTML
paragraph that will be broken into several
lines. The first line will be identified
by a fictional tag sequence. The other lines
will be treated as ordinary lines in the
paragraph.</P>
行会照如下样子打破:
THIS IS A SOMEWHAT LONG HTML PARAGRAPH THAT
will be broken into several lines. The first
line will be identified by a fictional tag
sequence. The other lines will be treated as
ordinary lines in the paragraph.
这个段落可能会被用户代理“重写”,用来包括为了::first-line的_虚构的标记序列_。这个虚构的标记序列帮助展示属性是怎样继承的。
<P><P::first-line> This is a somewhat long HTML
paragraph that </P::first-line> will be broken into several
lines. The first line will be identified
by a fictional tag sequence. The other lines
will be treated as ordinary lines in the
paragraph.</P>
如果一个伪元素被一个真正的元素打破,渴望的效果也能通过虚构标记序列先闭合然后再重开那个元素来描述。因此,如果我们给之前的段落加一个span元素:
<P><SPAN class="test"> This is a somewhat long HTML
paragraph that will be broken into several
lines.</SPAN> The first line will be identified
by a fictional tag sequence. The other lines
will be treated as ordinary lines in the
paragraph.</P>
用户代理能在为了::first-line插入虚构标记序列时模仿span的开始和结束标记。
<P><P::first-line><SPAN class="test"> This is a
somewhat long HTML
paragraph that will </SPAN></P::first-line><SPAN class="test"> be
broken into several
lines.</SPAN> The first line will be identified
by a fictional tag sequence. The other lines
will be treated as ordinary lines in the
paragraph.</P>
在CSS中格式化后第一行的定义
在CSS中,::first-line伪元素只能当依附到像块容器(例如块盒,inline-block,table-caption或者table-cell)上时才会有效果。
一个元素的格式化后第一行可以出现在一个在相同流(不是由于浮动或者定位而引起在流之外的块级子孙)中的块级子孙的内部。例如,在<DIV><P>This line...</P></DIV>中DIV的第一行就是P的第一行(假设P和DIV都是块级的)。
一个table-cell或者inline-block的第一行不能称为一个祖先元素的格式化后第一行。因此,在<DIV><P STYLE="display: inline-block">Hello<BR>Goodbye</P> etcetera</DIV>中,DIV格式化后第一行不是行“Hello”。
注意:在片段p><br>First...中的p的第一行不包含任何的字母(假设br在HTML4中是默认样式)。单词“First”不是在格式化后第一行上。
如果虚拟的::first-line伪元素的开始标记是恰好嵌套在最里边,UA应该扮演者围绕着块级元素。(由于CSS1和CSS2在这种情况下都是无记载的,作者不应该依赖这个行为。)例如,如下的虚拟的标记序列
<DIV>
<P>First paragraph</P>
<P>Second paragraph</P>
</DIV>
是
<DIV>
<P><DIV::first-line><P::first-line>First paragraph</P::first-line></DIV::first-line></P>
<P><P::first-line>Second paragraph</P::first-line></P>
</DIV>
::first-line伪元素和一个行内级元素很像,但是也有明确的限制条件。接下来的CSS属性应用到::first-line伪元素的:font属性,color属性,background属性,‘word-spacing’, ‘letter-spacing’, ‘text-decoration’, ‘vertical-align’, ‘text-transform’, ‘line-height’。UA也可以应用其他的属性。
在CSS继承期间,在第一行的一个子元素部分只能继承自::first-line伪元素上的能应用到::first-line伪元素上的属性。对于其他属性则是继承自第一行伪元素的非伪元素父级元素。(不在第一行的一个子元素部分往往继承自这个孩子的父元素。)
::first-letter伪元素
::first-letter伪元素描述了一个元素的第一个的字母,如果他不是在他的行上的其他内容(例如图片或者行内表格)之前。::first-letter伪元素可能用于“第一个字大写”和“首字下沉”,他们通常是印刷上的效果。
在第一个单词之前或者之后的标点符号应该包括在内。

如果第一个字母事实上是一个数字,那么::first-letter也会应用的。例如在“67 million dollars is a lot of money.”中的“6”。
注意:在一些情况下,::first-letter伪元素应该包括的不仅仅是一行中的第一个非标点符号字符。例如,组合字符必须和他们的基础字符保持在一起。另外,一些语言可以有关于怎样对待特定的字母组合的特殊的规则。UA的::first-letter的定义应该至少包括UAX29定义的默认字母群以及可以尽量合适的包括更多。例如,在荷兰语中,如果字母组合”ij”出现在一个元素的开头,他们都应该认为在::first-letter伪元素内。
如果构成::first-letter的字母不是在一个元素内,例如“<p>‘T…”中的“’T”,UA可以从其中一个元素、所有的元素中创建一个::first-letter伪元素或者简单不创建伪元素。
类似的,如果块的第一个字母不是在行的开头(例如由于双向重排),那么UA没必要创建伪元素。
例子:
接下来的CSS和HTML例子阐述了重叠的伪元素怎样相互影响。每一个P元素的第一个字母将会是绿色的,且font尺寸是24pt。格式化后第一行会是蓝色的,其余部分是红色的。
p { color: red; font-size: 12pt }
p::first-letter { color: green; font-size: 200% }
p::first-line { color: blue }
<P>Some text that ends up on two lines</P>
假设换行会在单词ends之前,对于这个片段来说,虚构的标记序列可能是:
<P>
<P::first-line>
<P::first-letter>
S
</P::first-letter>ome text that
</P::first-line>
ends up on two lines
</P>
注意
::first-letter元素是在::first-line元素内的。::first-line的属性会被::first-letter继承,但是如果在::first-letter设置了相同属性的话就会被覆盖掉。
第一个字母必须在格式化后第一行上。例如,在HTML片段<p><br>First...中,第一行不包含任何的字母,::first-letter不会匹配任何东西(假定HTML4中br是默认样式)。尤其他不会匹配“First”的“F”。
在CSS中应用
在CSS中,::first-letter伪元素应用到像块容器上,例如block, list-item, table-cell, table-caption, 和inline-block元素。注意:本规范未来的版本可能会允许伪元素应用到更多display类型上。
::first-letter伪元素能用到所有的包含文本的元素上,或者在相同流中的有文本的子孙元素上。UA应该扮演像是::first-letter伪元素的虚构的开始标记恰好在这个元素的第一个文本之前,即使那个第一个文本是在子孙元素中。
例子:
下面的这段HTML片段的虚构标记序列:
<div>
<p>The first text.
是
<div>
<p><div::first-letter><p::first-letter>T</...></...>he first text.
在CSS中一个table-cell或者inline-block的第一个字母不能是一个祖先元素的第一个字母。因此,在<DIV><P STYLE="display: inline-block">Hello<BR>Goodbye</P> etcetera</DIV>中,DIV的第一个字母不是“H”。事实上,DIV没有第一个字母。
如果一个元素在一个列表项(display:list-item)中,::first-letter应用到在标记marker之后的主盒中。UA可以忽略是‘list-style-position: inside’这样的列表项的::first-letter。如果一个元素有::before或者::after内容,::first-letter应用到这个元素的第一个字母上,包括那个内容。
例子:
在规则
p::before {content: "Note: "}之后,选择器p::first-letter匹配“Note”的“N”。
在CSS中一个::first-line伪元素和一个行内级元素很像,如果他的float属性是none的话;其他情况,他和一个浮动元素是很像的。接下来的属性应用到::first-letter伪元素上:font属性,‘text-decoration’, ‘text-transform’, ‘letter-spacing’, ‘word-spacing’ (恰当时候), ‘line-height’, ‘float’, ‘vertical-align’ (只有‘float’是‘none’), margin属性, padding属性, border属性, color属性, background属性。UA也可以应用其他属性。为了允许UA渲染一个印刷上的正确的首字下沉或者第一个字母大写,UA可以选择一个基于字母的形状的行高,宽和高,不想正常元素那样。
例子:
这个CSS和HTML例子展示了渲染第一个字母大写的一种可能。注意line-height是继承自
::first-letter伪元素的1.1的,但是在这个例子中,UA不同的计算第一个字母高,因此他不会导致在两行间任何的不必要的空隙。也注意第一个字母的虚拟的开始标记是在span历百年的,且因此第一个字母的font weight是normal,而不是和span一样是bold:
p { line-height: 1.1 }
p::first-letter { font-size: 3em; font-weight: normal }
span { font-weight: bold }
...
<p><span>Het hemelsche</span> gerecht heeft zich ten lange lesten<br>
Erbarremt over my en mijn benaeuwde vesten<br>
En arme burgery, en op mijn volcx gebed<br>
En dagelix geschrey de bange stad ontzet.

下边的CSS会创建一个两行的首字下沉效果:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN">
<HTML>
<HEAD>
<TITLE>Drop cap initial letter</TITLE>
<STYLE type="text/css">
P { font-size: 12pt; line-height: 1.2 }
P::first-letter { font-size: 200%; font-weight: bold; float: left }
SPAN { text-transform: uppercase }
</STYLE>
</HEAD>
<BODY>
<P><SPAN>The first</SPAN> few words of an article
in The Economist.</P>
</BODY>
</HTML>
这个自理可能会格式化为:

虚构的标记序列:
<P>
<SPAN>
<P::first-letter>
T
</P::first-letter>he first
</SPAN>
few words of an article in the Economist.
</P>
注意
::first-letter伪元素标签紧邻内容,然而::first-line伪元素的开始标记是插在块元素的开始标记之后右边的。
为了达到印刷上首字下沉格式化,用户代理可以粗略估计font尺寸,例如和baseline对齐。当格式化时图形轮廓也可以考虑在内。
空白
本段落故意死留白。(本段落以前定义::selection伪元素。)
::before和::after伪元素
::before和::after伪元素能用于描述在一个元素内容之前或者之后生成的内容。他们在CSS2.1中解释过了。
当::first-letter和::first-line伪元素应用到一个有::before或者::after生成内容的元素上时,他们应用这个元素的第一个字母或者第一行时是包括生成内容的。
关系选择器
后代选择器
有时,作者可能想选择器能描述在文档树中一个元素是另一个元素的后代。后代选择器表示的就是这样的关系。一个后代选择器是空格分隔的两个简单选择器序列。“A B”形式的选择器代表了元素B时一些祖先元素A的一个任意的后代。
例子:
例如考虑如下选择器:
h1 em
他代表了一个em元素是一个h1元素的后代。他正确有效的描述了如下片段局部:
<h1>This <span class="myclass">headline
is <em>very</em> important</span></h1>
接下来的选择器:
div * p
代表了一个p元素是一个div元素的孙子或者之后的后代。注意*两边的空格不是通用选择器的一部分;空格是一个连接符,表明div必须是一些元素的祖先,且那个元素必须是p的祖先。
接下来的选择器,合并了后代选择器和属性选择器,代表了一个元素
-
有href属性
-
在p内部,p在div内部
div p *[href]
子选择器
子选择器描述了两个元素间的孩子关系。子选择器是由大于号(U+003E, >)分离了两个简单选择器序列。
例子:
接下来的选择器代表了一个p元素时body的孩子:
body > p
接下来例子的例子合并了后代选择器和子选择器。
div ol>li p
它代表了p元素时li元素的后代;li必须是ol元素的孩子;ol元素必须是div的后代。提醒>两边的空格是可选的。
为了选择一个元素的第一个孩子信息,请看上边关于:first-child伪类。
兄弟选择器
有两种不同的兄弟选择器:相邻兄弟选择器和通用兄弟选择器。这两种情况,当考虑元素相邻事,非元素节点会被忽略。
相邻兄弟选择器
相邻兄弟选择器是用加号(U+002B, +)分离了两个简单选择器序列。在文档树中这两个序列代表的元素共享同样的父元素,且第一个序列代表的元素直接在第二个代表元素之前。
例子:
接下来的选择器代表了一个p元素直接在math元素之后:
math + p
接下来的选择器和上一个例子概念上很像,除了他增加了一个属性选择器——他给h1元素增加了一个约束,他必须有class=”opener”:
h1.opener + h2
通用兄弟选择器
通用兄弟选择器是用波浪号(U+007E, ~)分离了两个简单选择器序列。在文档树中这两个序列代表的元素共享同样的父元素,且第一个序列代表的元素在第二个代表元素之前。
例子:
h1 ~ pre
代表了pre元素跟着一个h1元素。他是正确有效的描述如下片段的局部:
<h1>Definition of the function a</h1>
<p>Function a(x) has to be applied to all figures in the table.</p>
<pre>function a(x) = 12x/13.5</pre>
计算选择器的特殊性
一个选择器的特殊性按如下计算:
-
计算在选择器中的ID选择器数目(=a)
-
计算在选择器中的类选择器,属性选择器以及伪类选择器的数目(=b)
-
计算在选择器中的类型选择器以及伪元素选择器的数目(=c)
-
忽略通用选择器
在否定伪类内像其他的那样计数,但是否定伪类本身布作为伪类计数。
把三个数字a-b-c连在一起,就给定了特殊性。
例子:
* /* a=0 b=0 c=0 -> specificity = 0 */
LI /* a=0 b=0 c=1 -> specificity = 1 */
UL LI /* a=0 b=0 c=2 -> specificity = 2 */
UL OL+LI /* a=0 b=0 c=3 -> specificity = 3 */
H1 + *[REL=up] /* a=0 b=1 c=1 -> specificity = 11 */
UL OL LI.red /* a=0 b=1 c=3 -> specificity = 13 */
LI.red.level /* a=0 b=2 c=1 -> specificity = 21 */
#x34y /* a=1 b=0 c=0 -> specificity = 100 */
#s12:not(FOO) /* a=1 b=0 c=1 -> specificity = 101 */
注意:重复出现的相同的简单选择器是允许的,且会增加特殊性。
注意:在HTML样式style属性的样式特殊性的规范是在CSS2.1中描述的。